Introduction to the Vision Problem
For decades, teaching computers to “see” was one of the most frustrating challenges in artificial intelligence. While humans can instantly glance at a photo and identify a cat, a car, or a coffee cup, a computer only sees a massive, flat matrix of numbers representing pixel color values. Early machine learning models attempted to solve image recognition by flattening these pixel arrays into a single line of data. This approach was computationally exhausting and, worse, it completely destroyed the spatial relationships between pixels. A pixel representing a cat’s ear is only meaningful when analyzed next to the pixels of the rest of the cat’s head.
The breakthrough came with the development of Convolutional Neural Networks (CNNs). By mimicking the biological processes of the human visual cortex, CNNs changed the landscape of computer vision forever, enabling machines to process, analyze, and understand visual data with superhuman accuracy.
The Biological Inspiration Behind the Algorithm
The architecture of a CNN is heavily inspired by groundbreaking neurobiological research from the 1950s and 60s. Scientists David Hubel and Torsten Wiesel discovered that neurons in the visual cortex of animals respond to specific, localized stimuli. Some neurons only fire when they see a vertical edge, while others respond only to horizontal lines or specific angles. The brain processes vision in a layered, hierarchical manner—piecing together simple edges to form shapes, and shapes to form complex objects.
CNNs replicate this exact hierarchical structure. Instead of looking at an entire image at once, a CNN looks at small, overlapping patches of the image, gradually building up a comprehensive understanding of the whole picture through multiple hidden layers.
The Core Architecture of a CNN
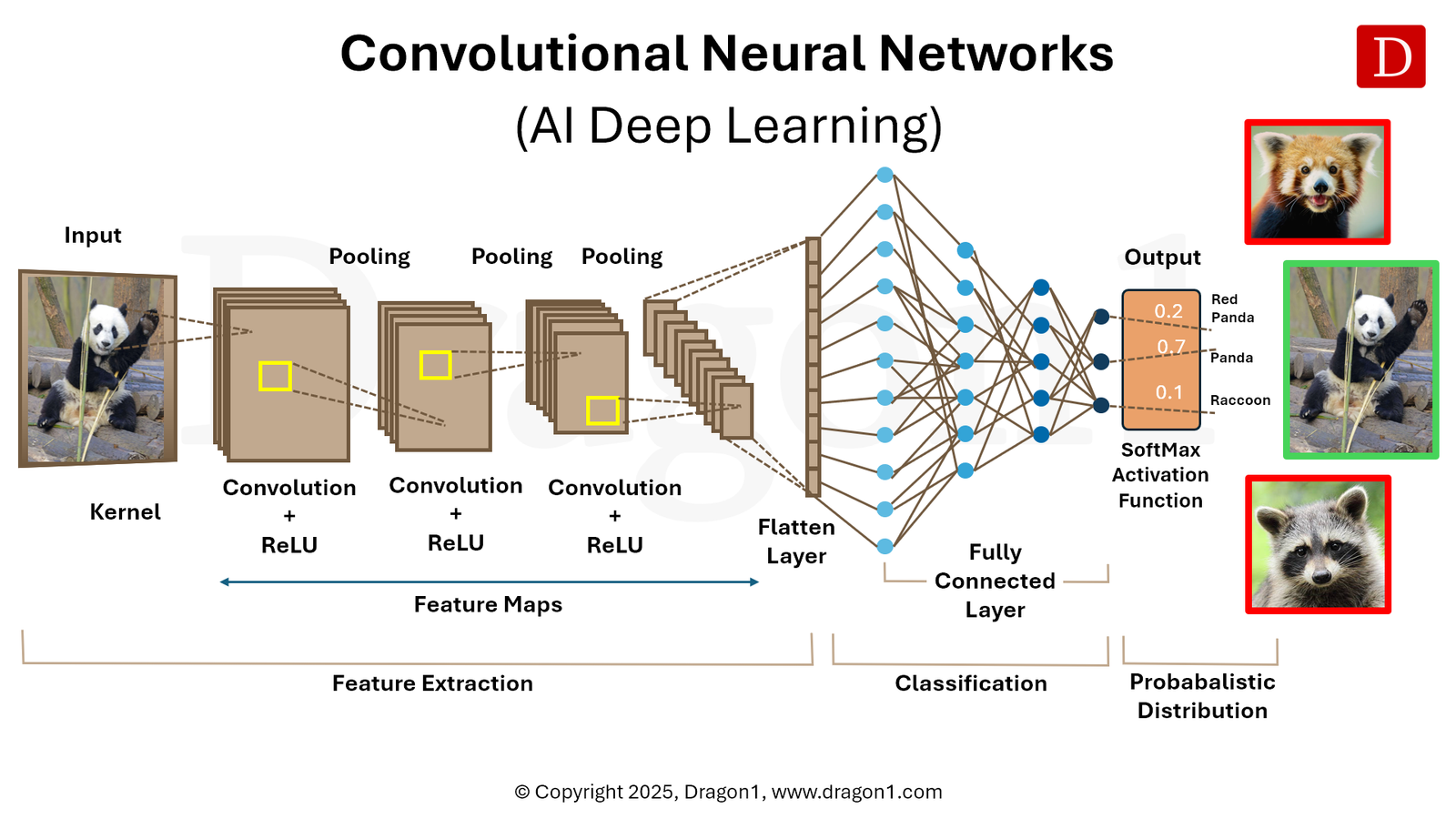
To understand how a CNN achieves such high accuracy, we have to break down its unique multi-layered architecture. A standard CNN is primarily composed of three types of layers: Convolutional Layers, Pooling Layers, and Fully Connected Layers.
The Convolutional Layer: The Feature Extractor
This is the core building block of the network. The convolutional layer uses a mathematical operation called a “convolution” to extract features from the input image. It involves a small matrix of weights called a “filter” or “kernel” (often 3×3 or 5×5 pixels in size).
This filter slides—or “convolves”—across the entire image. At each step, it multiplies its own weights by the pixel values it is hovering over and sums them up. This operation creates a new two-dimensional matrix known as a “Feature Map.”
Different filters are trained to look for different things. In the first layer, filters might act as edge detectors. As the network gets deeper, the filters combine these simple edges to detect more complex patterns, like textures, eyes, wheels, or leaves.
To introduce non-linearity into the network (since real-world data is rarely linear), the output of the convolution operation is passed through an activation function. The most common is the Rectified Linear Unit (ReLU), mathematically expressed as $f(x) = \max(0, x)$. This function simply replaces all negative pixel values in the feature map with zero, helping the network learn complex patterns faster and mitigating the vanishing gradient problem during training.
The Pooling Layer: Dimensionality Reduction
After a convolutional layer, the network typically applies a Pooling Layer (or downsampling layer). The purpose of pooling is to reduce the spatial dimensions (width and height) of the feature maps while retaining the most critical information.
The most popular method is “Max Pooling.” If you use a 2×2 max pooling filter, the algorithm looks at a 2×2 block of pixels in the feature map and simply outputs the maximum value from that block, discarding the rest.
This serves three critical functions:
- Reduced Computation: By shrinking the data size, it drastically reduces the number of parameters the network has to calculate, preventing the system from running out of memory.
- Spatial Invariance: It helps the network recognize objects even if they are slightly shifted, rotated, or distorted in the image. A cat is still a cat, whether it’s in the center of the frame or off to the left.
- Overfitting Prevention: By dropping less important data, it forces the network to focus only on the most dominant features, making the model more generalized and accurate on new, unseen data.
The Fully Connected Layer: The Decision Maker
After the image has passed through multiple alternating Convolutional and Pooling layers, the high-level reasoning happens in the Fully Connected (FC) layer.
At this stage, the 2D feature maps are “flattened” into a single, long 1D vector of numbers. This vector is fed into a traditional neural network. Every neuron in this layer is connected to every neuron in the previous layer. The FC layer takes the complex features extracted by the convolutional layers and uses them to classify the image into predefined categories (e.g., determining with 92% probability that the image contains a car, and 8% probability it contains a truck).
Real-World Applications Revolutionized by CNNs
The theoretical elegance of CNNs has translated into massive real-world impact across dozens of industries.
- Medical Imaging and Diagnostics: CNNs are fundamentally changing healthcare. They are routinely trained on thousands of X-rays, MRIs, and CT scans to detect anomalies like tumors, micro-fractures, or early signs of pneumonia. In many specialized tasks, CNNs now boast lower error rates than human radiologists, serving as a powerful second opinion that never suffers from eye fatigue.
- Autonomous Vehicles: Self-driving cars rely entirely on advanced computer vision to navigate the physical world. CNN-based architectures, like YOLO (You Only Look Once), process real-time video feeds from the car’s cameras to instantly detect pedestrians, read stop signs, and track the trajectory of other vehicles at highway speeds.
- Mobile Gaming and Esports: As mobile hardware becomes more powerful, CNNs are being leveraged to optimize competitive gaming environments. Developers use CNN-based algorithms to analyze frame-by-frame player behavior to identify aimbots and wallhacks, creating robust, automated anti-cheat systems. Additionally, AI upscaling techniques use lightweight neural networks to enhance low-resolution textures in real-time, allowing visually stunning games to run smoothly on mid-range mobile devices without draining the battery.
- Retail and E-commerce: Visual search is becoming standard. Companies like Amazon and Pinterest use CNNs to allow users to upload a photo of a shirt or a piece of furniture, instantly analyzing the image’s features to recommend visually similar products from their massive databases.
The Future: Challenges and Next Steps
Despite their dominance, CNNs are not without limitations. They require massive amounts of labeled data to train effectively, and the training process consumes immense computational power, usually requiring clusters of high-end GPUs. Furthermore, they can sometimes be fooled by “adversarial attacks”—where a few specifically altered pixels (invisible to the human eye) can cause the CNN to misclassify a stop sign as a speed limit sign.
Today, the AI community is exploring new frontiers. Vision Transformers (ViTs), an architecture adapted from natural language processing, are beginning to challenge CNNs for the top spot in image recognition benchmarks. However, due to their efficiency and proven track record, Convolutional Neural Networks will remain the backbone of applied computer vision for years to come.